AI Agent
0. Refercence Paper
The Rise and Potential of Large Language Model Based Agents: A Survey
Voyager: An Open-Ended Embodied Agent with Large Language Models
1. What is an agent
Typically in AI, an agent refers to an artificial entity capable of perceiving its surroundings using sensors, making decisions, and then taking actions in response using actuators.
- The term agent is meaning to emphasize the autonomy of the entity. Istead of a passive assistant, an agent is able to handle the details on its own.
As AI advanced, the term “agent” found its place in AI research to depict entities showcasing intelligent behavior and possessing qualities like autonomy, reactivity, pro-activeness, and social ability
This picture provided an envision(WITH GENSHIN IMPACT):
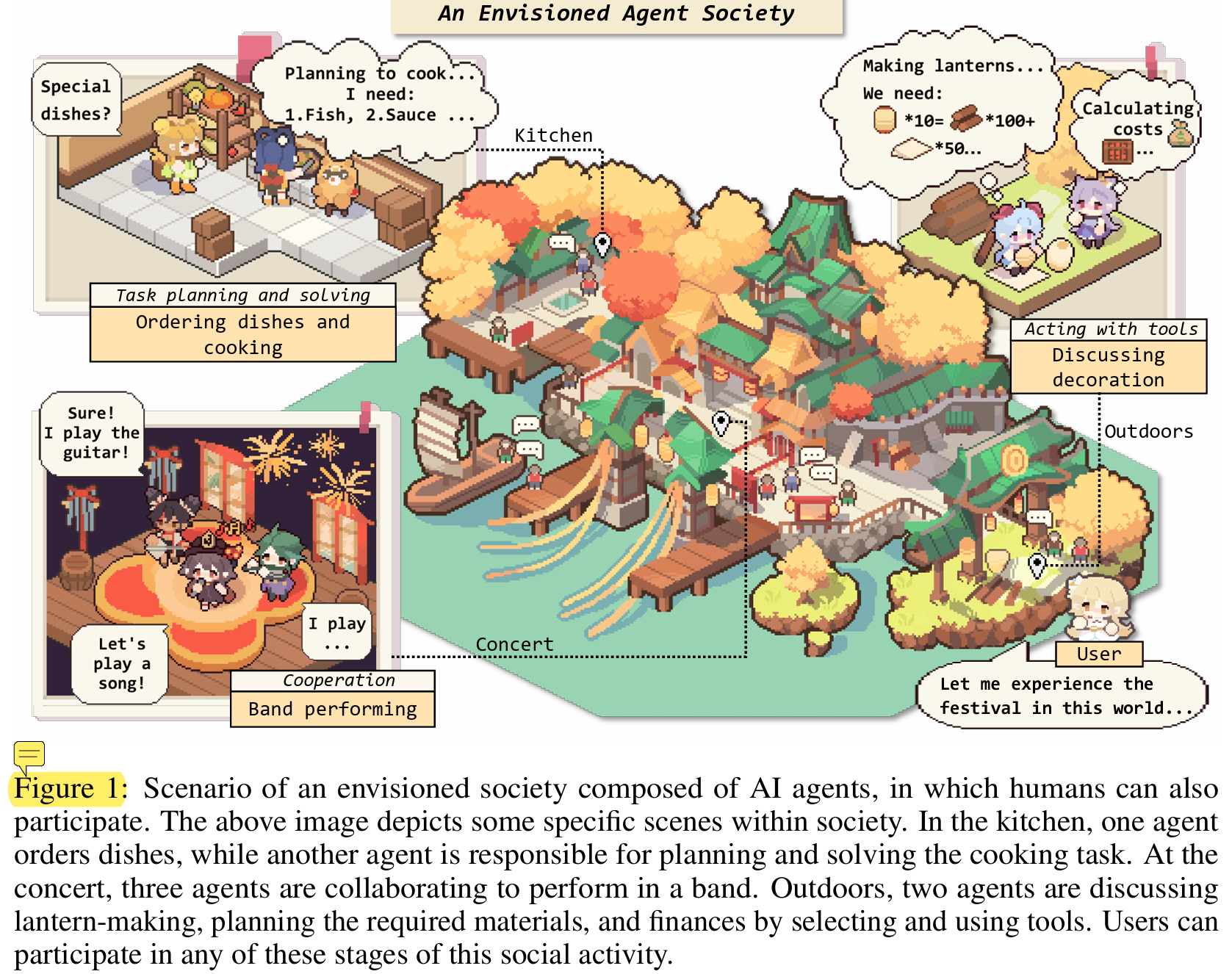 An Envisioned Agent Society
An Envisioned Agent Society
2. Framework
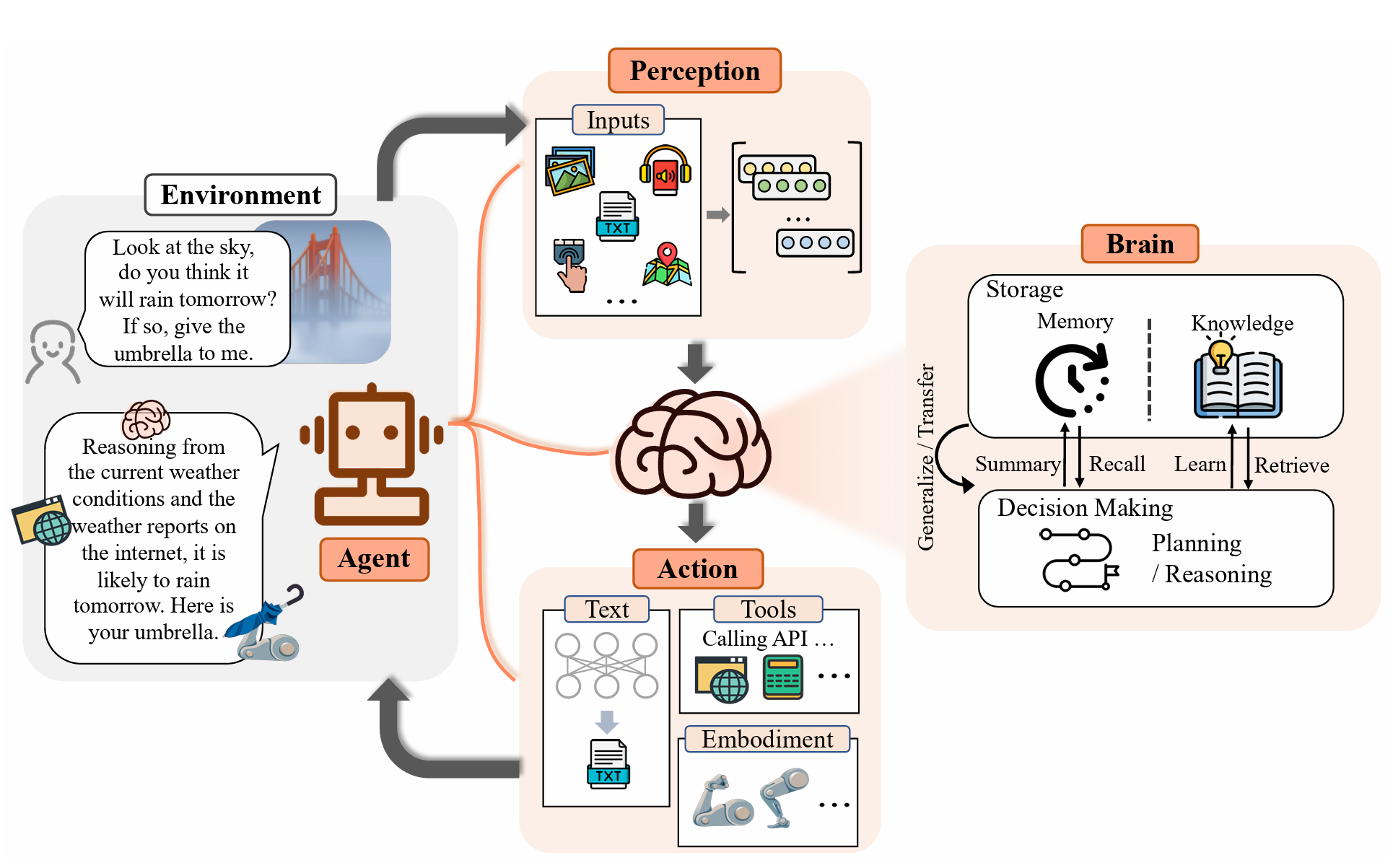 Framwork given by the ref paper: The Rise and Potential…
Framwork given by the ref paper: The Rise and Potential…
Different research propose different frameworks for agents. In general, an agent framework should include:
2.1 Input
The agent should be able to perceive the environment. The input is multimodal, including visual, audio, and text. The input model should be able to handle the multimodal input. Either by translate them in to natural language, or by using a multimodal model.
2.2 Processing
The agent should be able to process the input. Before LLM, RL are used in agent:
Nonetheless, reinforcement learning faces challenges including long training times, low sample efficiency, and stability concerns, particularly when applied in complex real-world environments.
Along with Meta-learning:
Furthermore, meta-learning has also been introduced to AI agents. Meta-learning focuses on learning how to learn.
And LLM has provide a new way to process the input:
Specifically, they employ LLMs as the primary component of brain or controller of these agents and expand their perceptual and action space through strategies such as multimodal perception and tool utilization. These LLMbased agents can exhibit reasoning and planning abilities comparable to symbolic agents through techniques like Chain-of-Thought (CoT) and problem decomposition.
LLM contains properties suitable for agent, including Autonomy, Reactivity, Pro-activeness and Social ability.
2.3 Output
The agent should be able to take actions. The output should also be multimodal.
3. Details in Processing
LLM serve as the agent’s central processor. Whats the key difference between a LLM like GPT and an agent as mentioned above?
The common part of the architecture given in reference papers about processing is the ability to memeorize, reason and plan. These three parts are intertwined and can be seen as a loop.
3.1 Memory
Memory is the basis of many further processing. The agent should be able to store and retrieve memories.
3.1.1 Store
ChatGPT is able to retain memory from previous conversation, by appending historial conversation to each subsequent input. This method utilize the attention mechanism in Transformer. But comes with a token cost and a limited text window.
A more human-like way is to summarize the memory, including calling the LLM again to generate a summary.
Using embedding vectors to compress text and enhance retrival is also a common approach and can be combined with summarize method.
3.1.2 Retrieve
We will cover the details of this part in later examples.
A significant approach in automated retrieval considers three metrics: Recency, Relevance, and Importance. The memory score is determined as a weighted combination of these metrics, with memories having the highest scores being prioritized in the model’s context.
3.2 Reasoning
Specifically, the representative Chain-of-Thought (CoT) method [95; 96] has been demonstrated to elicit the reasoning capacities of large language models by guiding LLMs to generate rationales before outputting the answer.
The key of reasoning is the COT method: Calling the LLM recursively to generate rationales.
3.3 Planing
Planing requires a hierarchical structure. The agent should be able to generate a high-level plan, and then recursively generate detailed actions.
4. Experiment Details
Here’s two specific realization of the framework.
4.1 Smallville
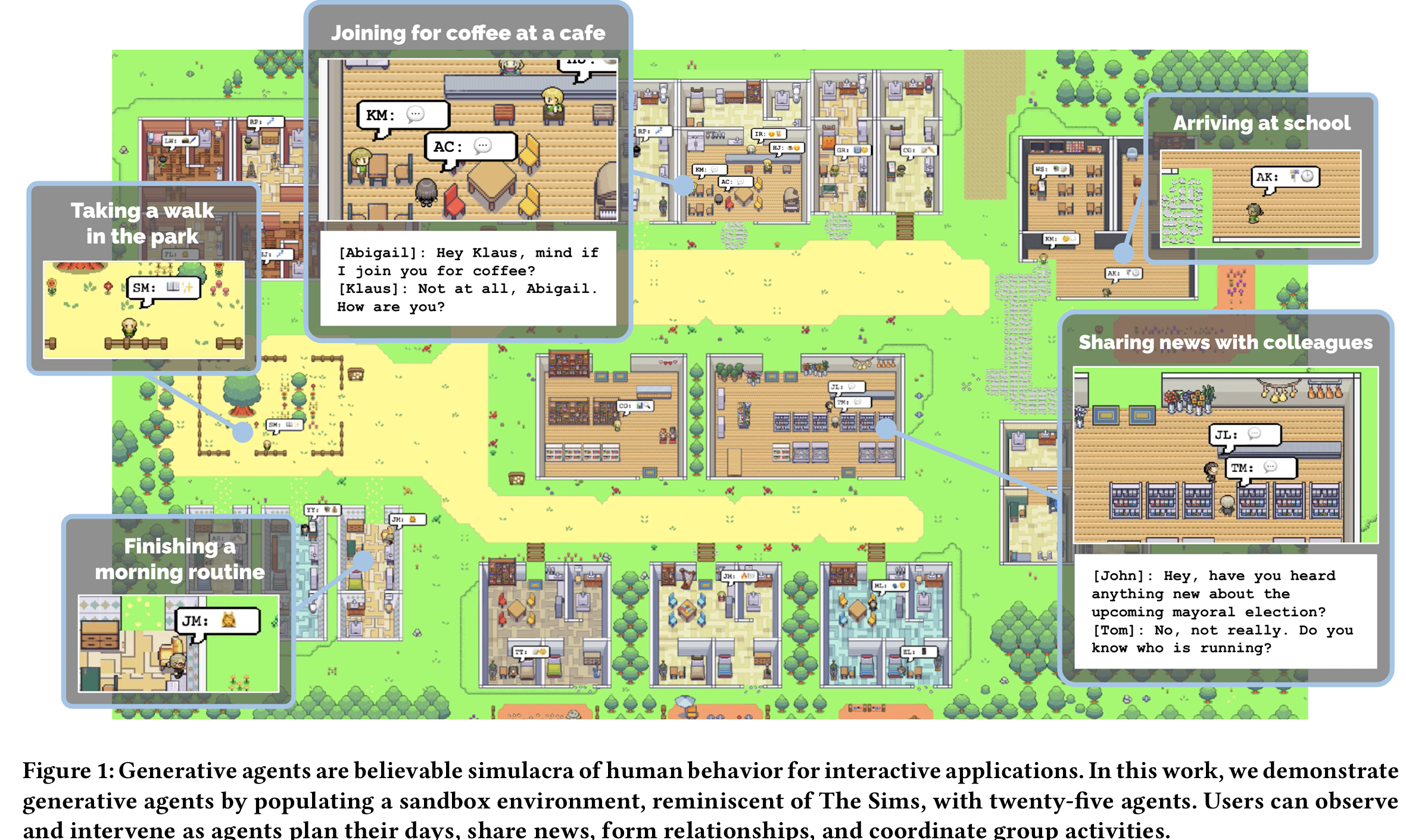 Smallville
Smallville
The researcher in built a small town with 25 agents. Each agent has a unique identity, including their occupation and relationship with other agents. The agent will generate a sentence describing their current action at each time step. The agent can also interact with each other, like spreading information, building relationship and collaborating.
We authored one paragraph of natural language description to depict each agent’s identity, including their occupation and relationship with other agents, as seed memories.
During the two simulated days, an agent successfully organized a wedding for a couple, and another agent successfully ran for mayor. These emergent behaviors are the result of the agent’s ability to spread information, build relationship and collaborate. The agent also made some mistakes, like forgetting, fabricating and breaking character.
The research only uses gpt3.5 as gpt4 is not available to the researchers yet.
4.1.1 Generative Agent Architecture
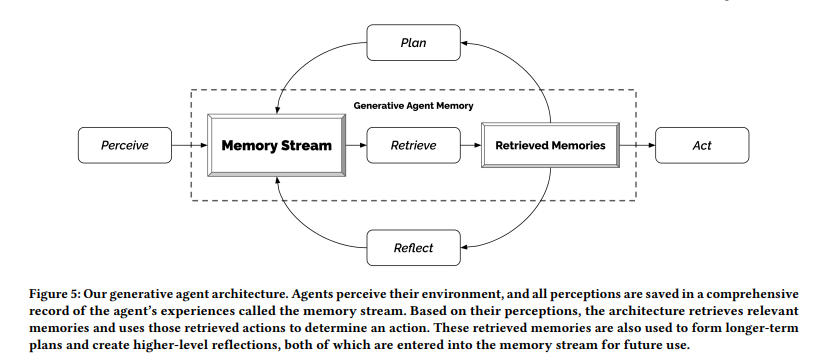
Underlying this behavior is a novel agent architecture that combines a large language model with mechanisms for synthesizing and retrieving relevant information to condition the language model’s output. Without these mechanisms, large language models can output behavior, but the resulting agents may not react based on the agent’s past experiences, may not make important inferences, and may not maintain long-term coherence.
The key part of the architecture is the memory stream. The memory stream is a list of memory objects, where each object contains a natural language description, a creation timestamp, and a most recent access timestamp. The memory stream is used to store the agent’s experience. The agent can retrieve memories from the memory stream, and use them to generate a sentence describing their current action. The agent can also use the memory stream to generate a high-level plan, and then recursively generate detailed actions.
4.1.1 Memory
Approach: The memory stream maintains a comprehensive record of the agent’s experience. It is a list of memory objects, where each object contains a natural language description, a creation timestamp, and a most recent access timestamp. The most basic element of the memory stream is an observation, which is an event directly perceived by an agent.
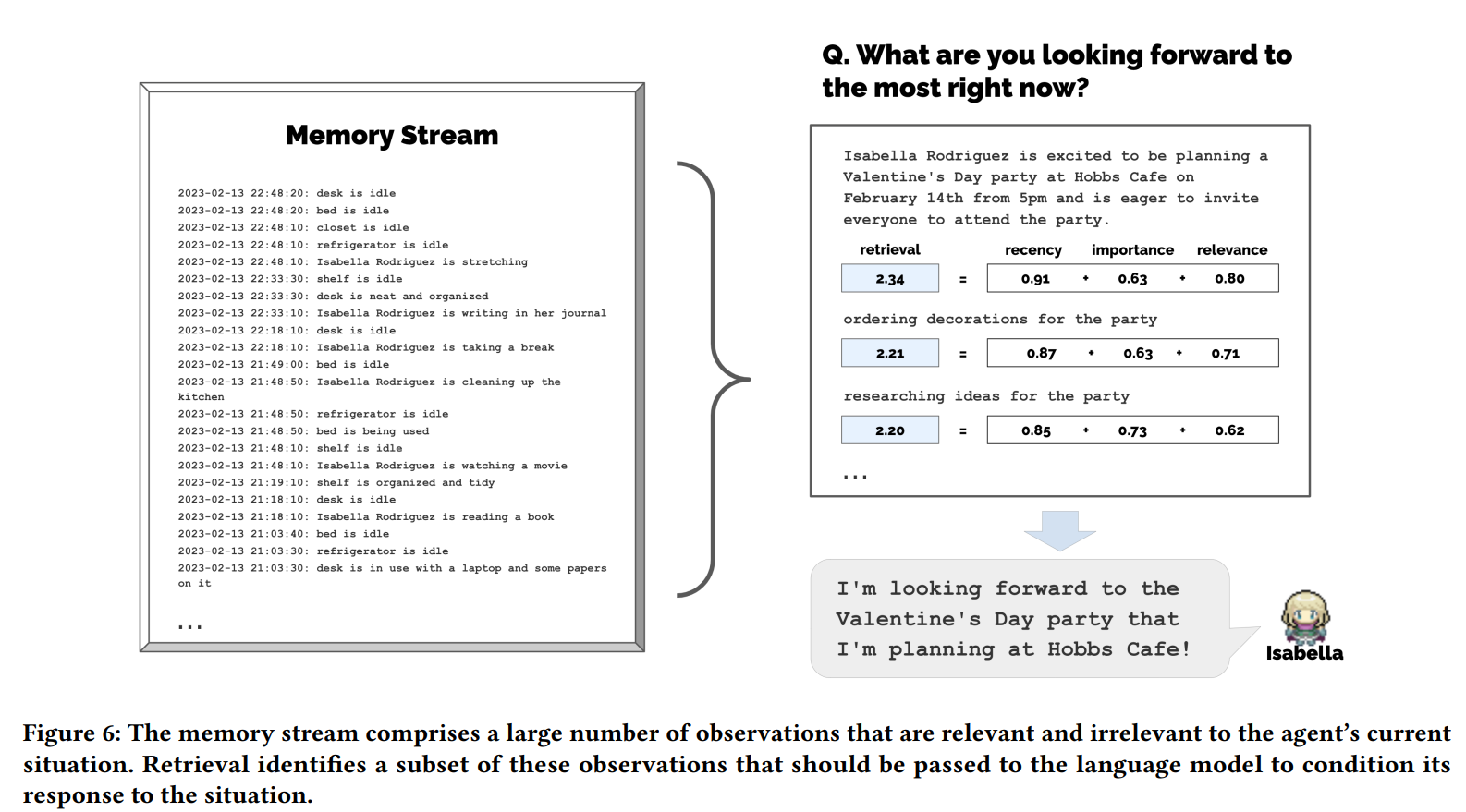
4.1.2 Retrive
Our architecture implements a retrieval function that takes the agent’s current situation as input and returns a subset of the memory stream to pass on to the language model.
The paper proposes three metrics to calculate the weight of a memory: Recency, Relevance, and Importance. The memory score is determined as a weighted combination of these metrics, with memories having the highest scores being prioritized in the model’s context.
- Recency is calculated using an exponential decay function from the last access timestamp.
- Importance is calculated by prompting the language model with a memory object and ask the model to rank a importance score.
- Relevance is calculated by using LLM to generate embedding vectors for each memory object, and then calculate the cosine similarity between the embedding vector of the memory and the query.
The three parameters are normalized with a minimax scaler, and then added together to get the final weight.
4.1.3 Reflection
Challenge: Generative agents, when equipped with only raw observational memory, struggle to generalize or make inferences.
The purpose of the reflection module is to synthesize memories into higher-level inferences over time, enabling the agent to draw conclusions about itself and others to better guide its behavior.
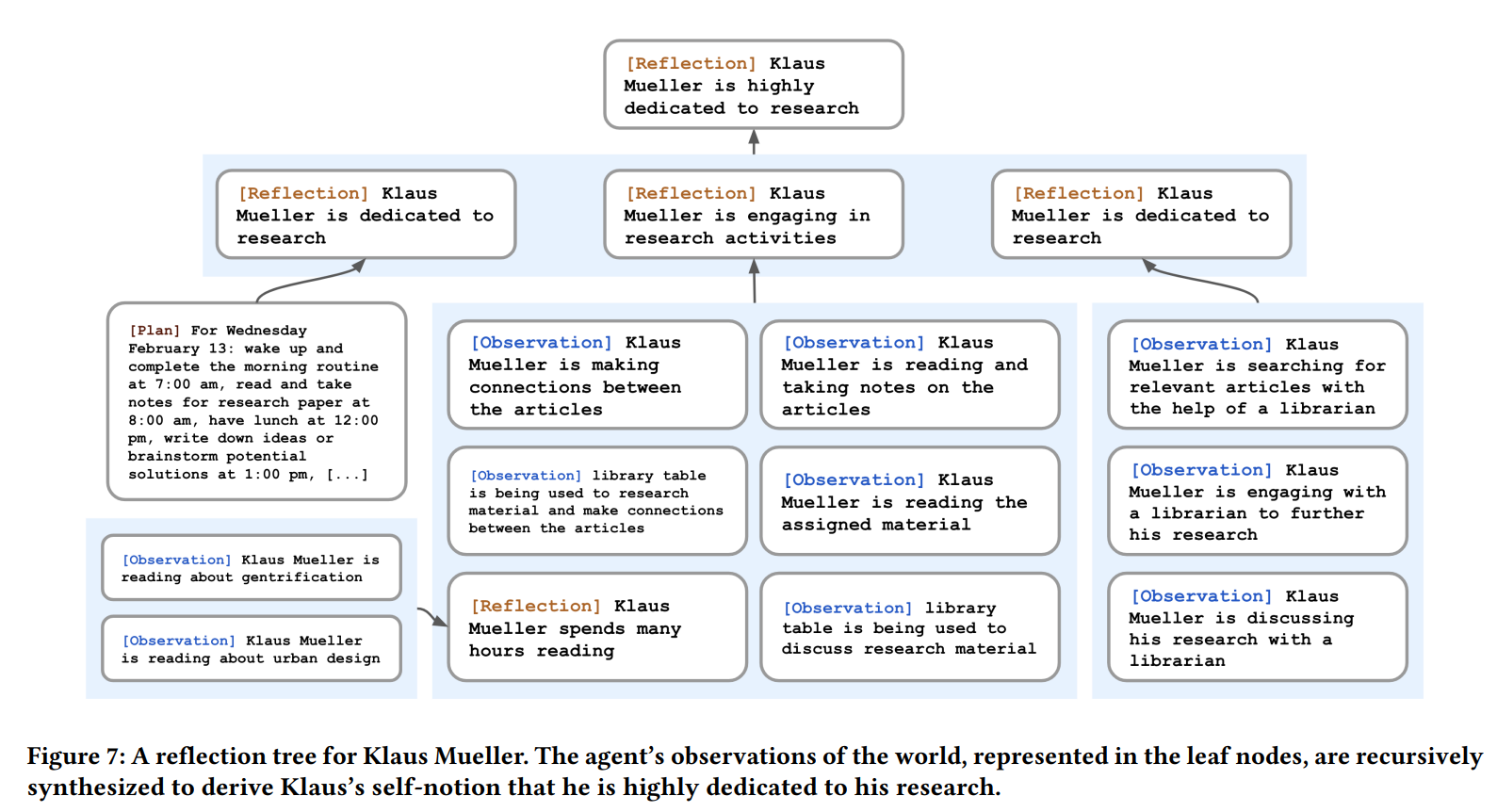 Reflection
Reflection
Reflection is also been treated as a type of memory and can be retrieved and reflected again.
Approach: We introduce a second type of memory, which we call a reflection. Reflections are higher-level, more abstract thoughts generated by the agent. Because they are a type of memory, they are included alongside other observations when retrieval occurs. Reflections are generated periodically; in our implementation, we generate reflections when the sum of the importance scores for the latest events perceived by the agents exceeds a threshold
To generate a reflection, the agent first promt LLM to generate questions based on recent memories:
“Given only the information above, what are 3 most salient highlevel questions we can answer about the subjects in the statements?”
Then the agent use the retrieval module to prompt LLM to generate answers to the questions. The agent will also ask LLM to provide the citation and create a link between them.
4.1.4 Planning
While a large language model can generate plausible behavior in response to situational information, agents need to plan over a longer time horizon to ensure that their sequence of actions is coherent and believable.
Approach: Plans describe a future sequence of actions for the agent, and help keep the agent’s behavior consistent over time. A plan includes a location, a starting time, and a duration.
The plan is created top-down. The agent first generate a high-level plan, and then recursively generate detailed actions.
- Plan is also stored in memory stream.
4.1.5 Reacting
Plan can not cover all the situations. The agent should be able to react to unexpected events, which requires updating the plan dynamically. The agent would perceive the enviroment and decide wether to update the plan or not. Dialouge is also usually happeneds as a reaction.
4.2 Voyager
We introduce VOYAGER, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. VOYAGER consists of three key components: 1) an automatic curriculum that maximizes exploration, 2) an ever-growing skill library of executable code for storing and retrieving complex behaviors, and 3) a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement.